



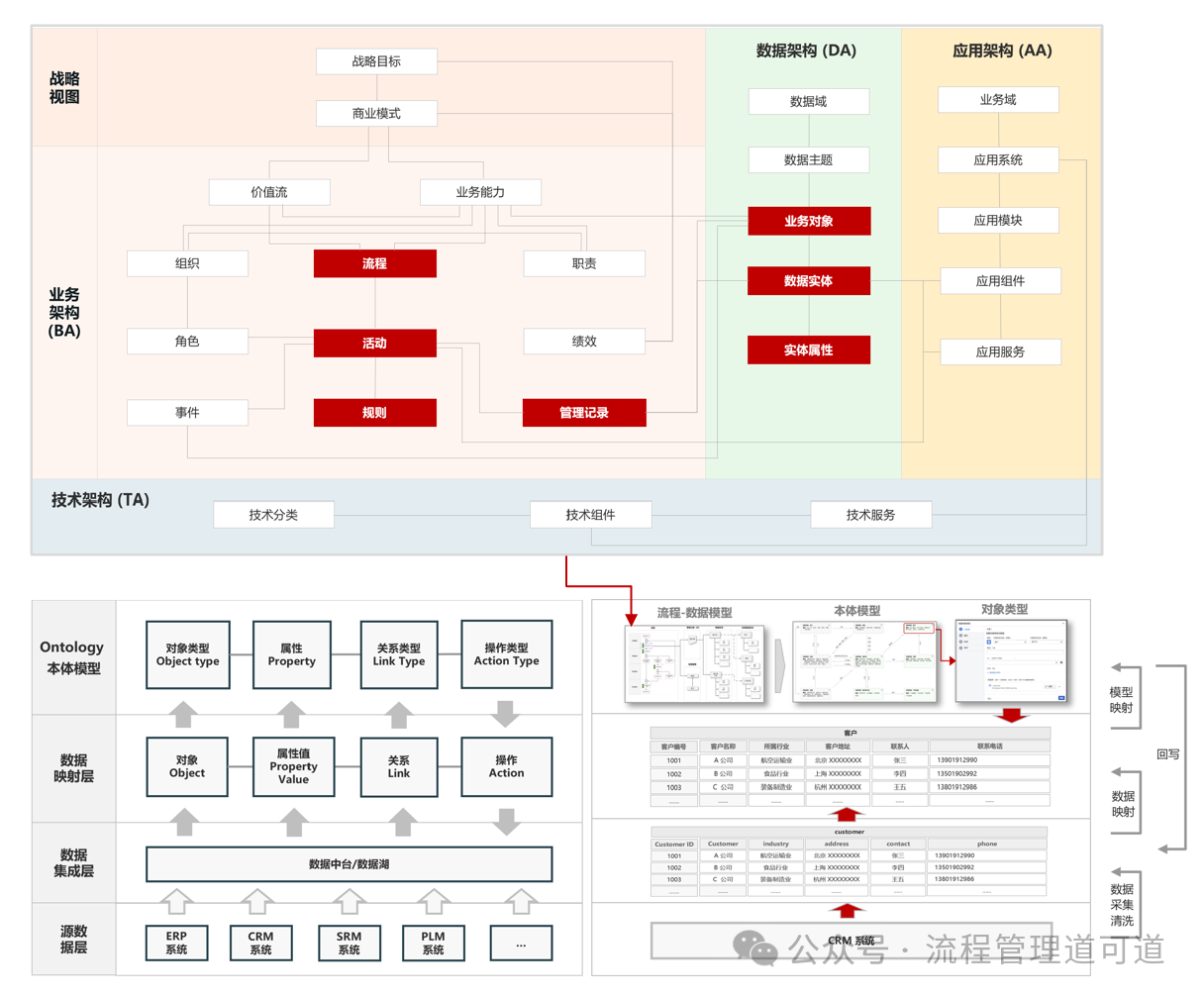
在《业务过程数字化和Palantir Ontology (上)》、《业务过程数字化与Palantir Ontology (中)》这两篇文章中,我们论证了【流程-数据模型】的本质就是「流程本体模型」。
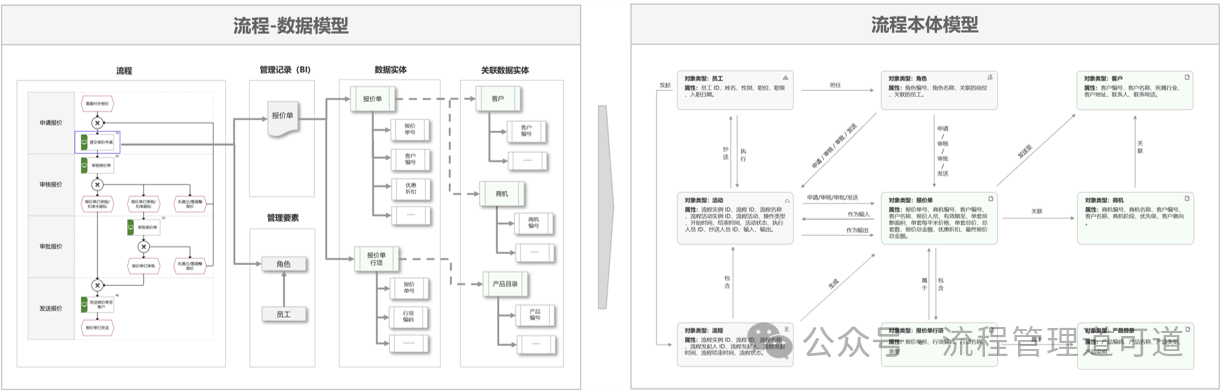
在上两篇文章中,我们以博阳家居的【销售报价流程】为例,构建了上图所示的【流程-数据模型】和「流程本体模型」,进而证明了当【流程-数据模型】构建完成后其实「流程本体模型」也同步构建完成了,因为「流程本体模型」中需要描述的内容和语义,在【流程-数据模型】中已经完整描述了。
有了上述模型,下一环节就是通过“数据映射”构建“数据+模型”的“业务数字孪生体”了。Palantir 的最大特色就是在这个环节做到了极致的工程化落地,实现了真正可用、可推演、可闭环的体系。
01—Palantir Foundry 工具平台
前文已经阐述过,EBPM 方法论认为 Palantir 与众不同之处不是诸如 “本体论” 之类的概念创新,而是构建 “业务数字孪生体” 的实践创新,是极致的工程化落地。Palantir 公司出品的软件工具平台则是其工程化落地的载体。抛开 Palantir 在政府及国防方面的工具平台 Gotham,对于企业数字化管理来说,Palantir 软件工具平台主要由以下三个产品构成:
1)Palantir Foundry(商业企业数据操作系统):这个平台就是用来构建「本体模型」,实现“数据映射”,并基于“数据+模型”的“业务数字孪生体”实现数字化设计、执行、监控、行动 PDCA 管理闭环的核心工具平台。此平台主要有以下四个方面的功能:
本体驱动建模:基于 Ontology 构建业务语义模型,实现数据与业务逻辑的深度绑定。
全域数据治理:统一接入、清洗、管理生产、供应链、销售、财务等全业务数据。
全链路分析工具:提供可视化分析、地理空间分析、时间序列分析、情景模拟、低代码应用开发。
闭环运营:分析结果可直接写回本体,驱动业务流程自动化与持续优化。
2)Apollo(底层部署与运维平台):这个基础平台主要用来支撑 Palantir平台的可靠运行,主要功能包括:部署、升级、系统运行监控和运维、系统安全管理等。
3)AIP(人工智能平台):生成式 AI 模型与业务操作的连接层,将大模型能力安全嵌入核心业务流程。AIP平台提供了生成式AI 能力与 Foundry 中本体模型的结合功能,是「本体模型」的 AI应用层。
本文将结合 Palantir Foundry 平台来介绍 “业务过程数字化” 的 “数据映射”环节,毕竟在这个方面 Palantir 是绝对的业界翘楚。而 “数据映射” 的关键不是方法论,而是工程实践,说得直白点,就是得真干!
02—基于「对象类型」自动生成物化「属性表」
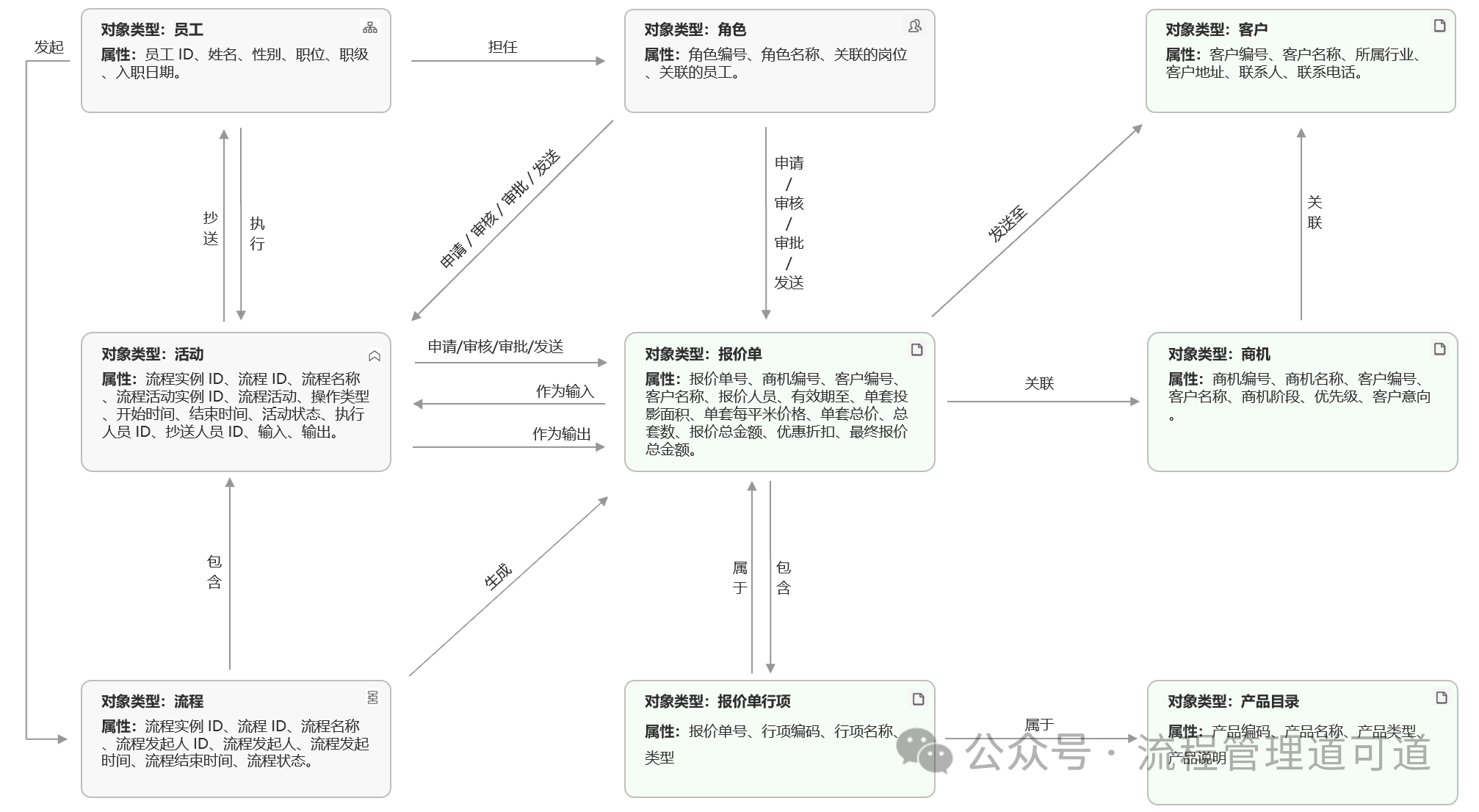
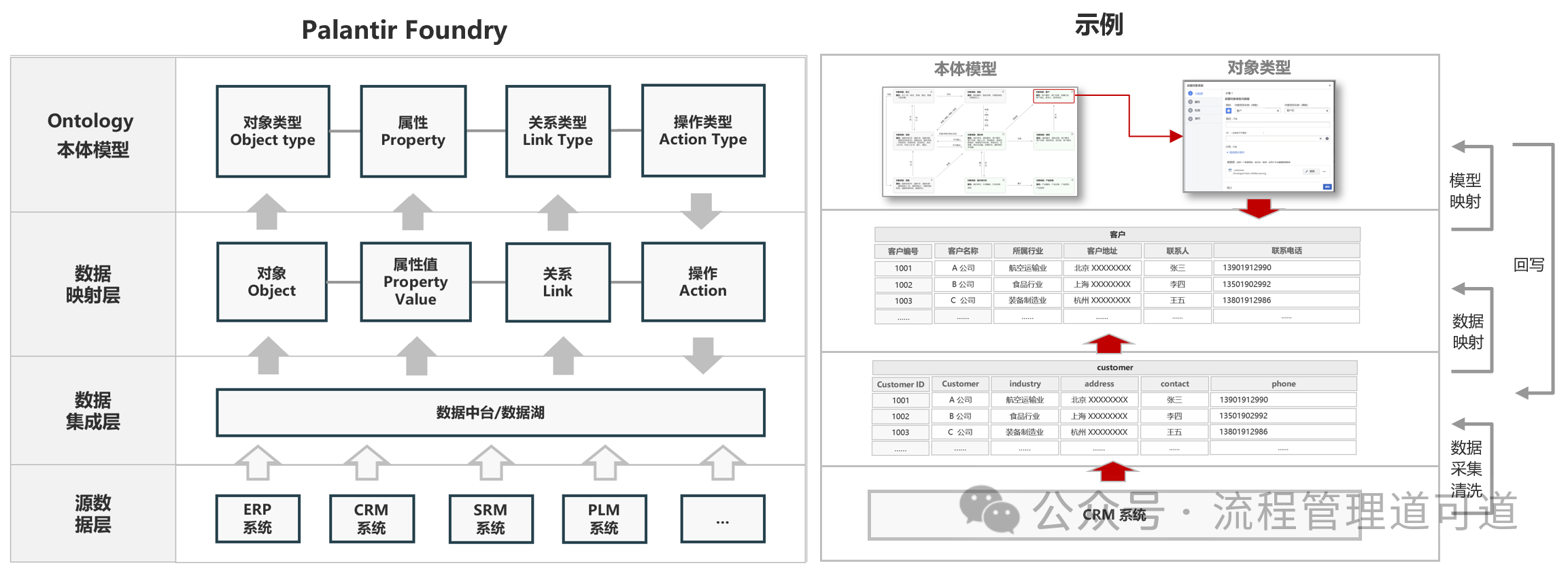
当我们在 Palantir Foundry平台中完成了上图所示的由「员工」、「活动」、「流程」、「角色」、「报价单」、「报价单行项」、「客户」、「商机」、「产品目录」9个「对象类型」和 17 组「关系类型」构成的销售报价流程的「本体模型」后。基于每个「对象类型」及其「属性」,可以在Foundry平台中自动生成一张物理表,也就是「属性表(Object Type Property Table)」。它不是手动创建的,而是由「本体模型」自动生成的。
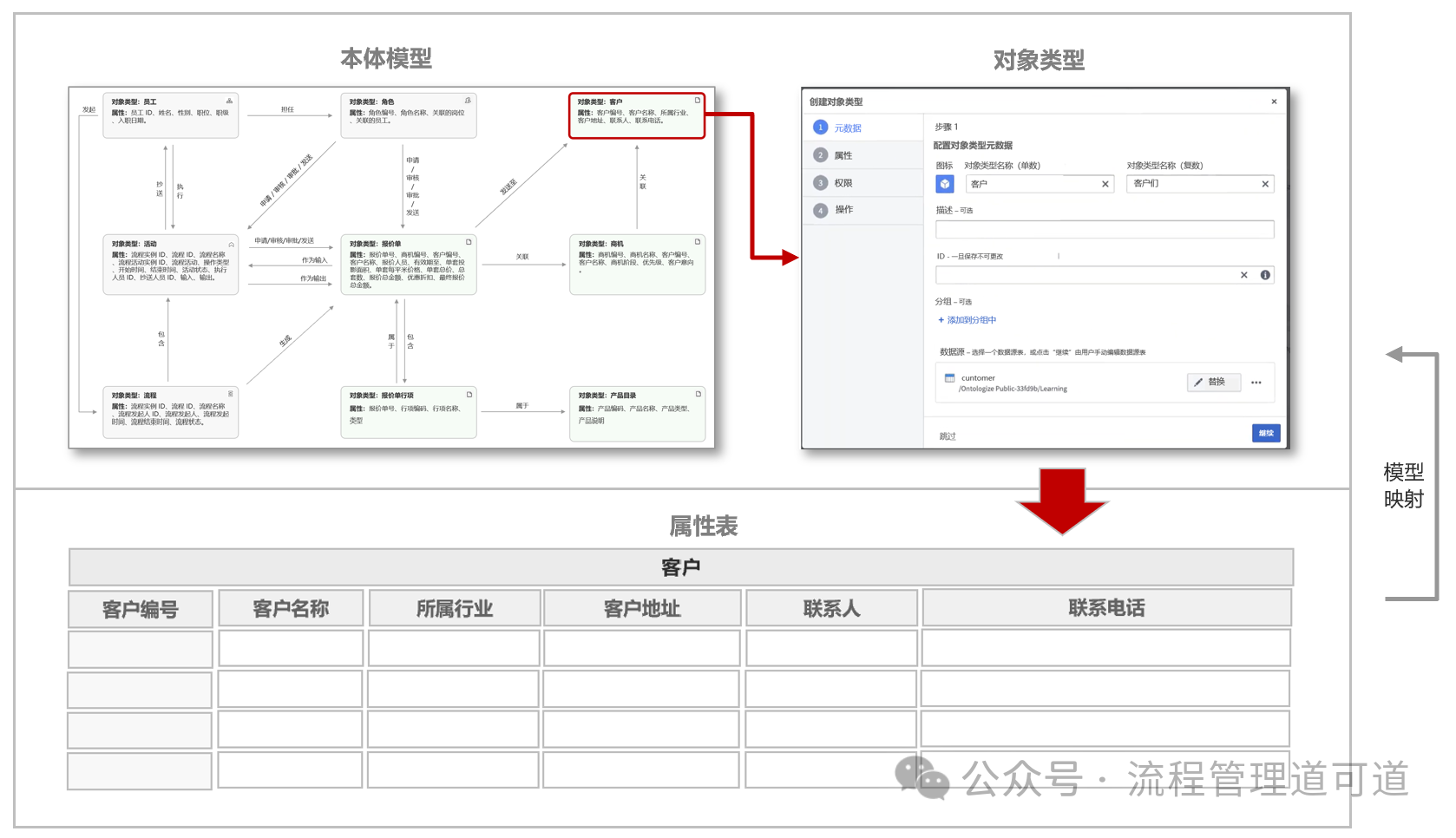
如上图所示,「属性表(Object Type Property Table)」是本体模型对原始数据做了结构化、索引化、统一格式后的 “物化视图存储”,用来支撑高速查询、关联、切片分析,而不是简单存原始数据。
要在 Foundry 平台自动生成「属性表(Object Type Property Table)」必须满足两个条件:
1)「对象类型」已绑定 「源数据表」,并完成了字段映射(列 → 属性)、主键(Primary Key) 与标题键(Title Key) 配置。
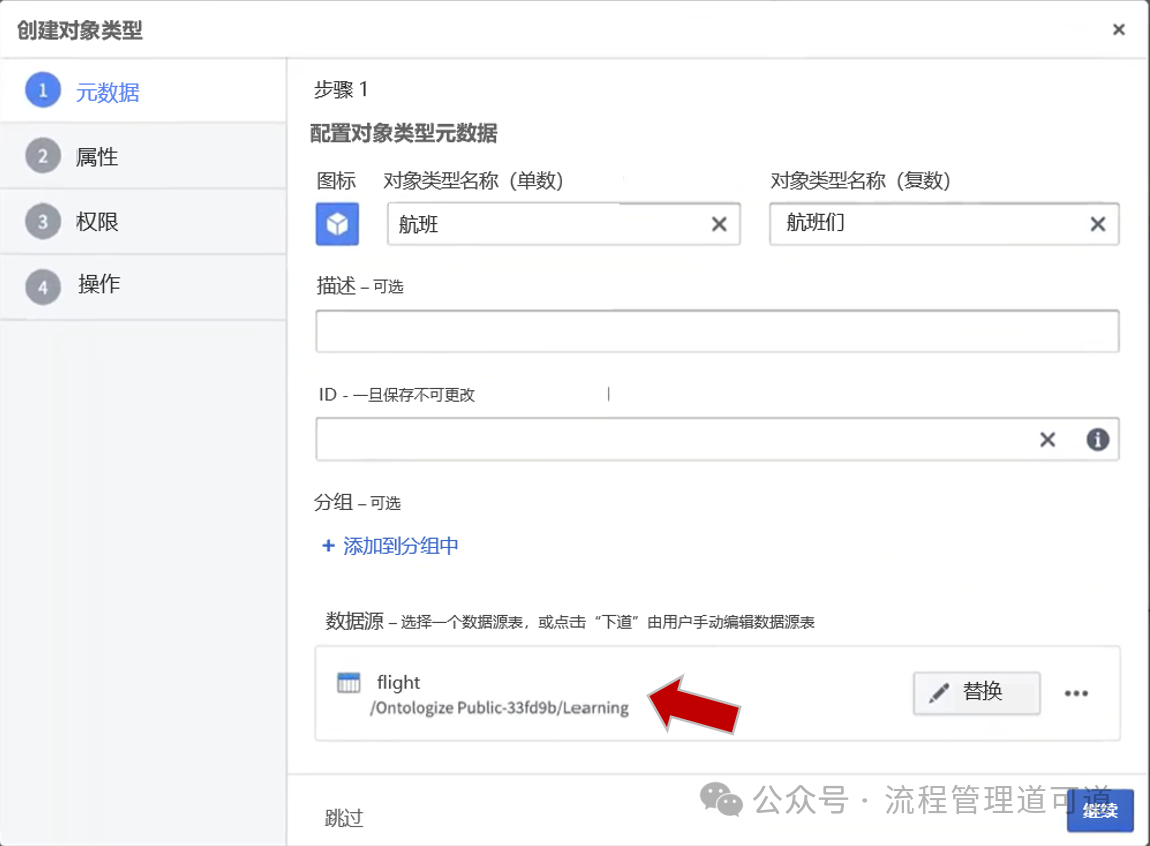
上图红色箭头所示是就是在Palantir Foundry将一个「对象类型」绑定「源数据表」的地方。
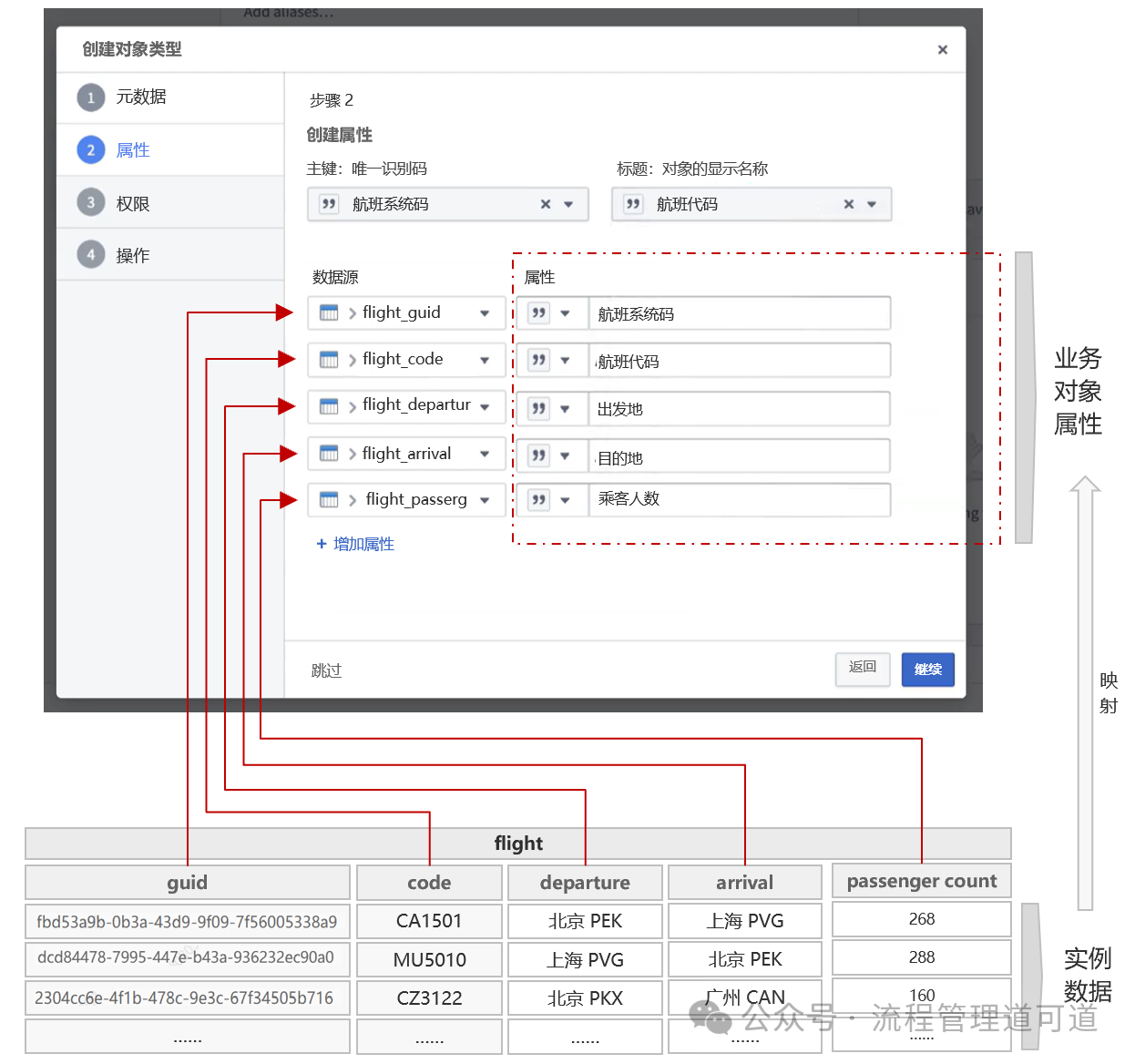
上图所示是Palantir Foundry中针对一个「对象类型」定义「属性」、「主键(Primary Key)」 与「标题键(Title Key)」并将这些「属性」与「源数据表」字段进行映射的地方。
总之,上述这些工作构建了「本体模型」与「源数据表」的映射关系。要实现这些功能,必须有一个工具平台支撑,目前国内企业中广泛建设的“数据中台“ 应可以实现此项功能。
事实上,Palantir Foudry 提供了完整的数据中台功能,只不过相较于传统意义上的数据中台,Palantir Foudry 还进一步提供和决策和执行的相关功能,构建了“数据-决策-执行”的闭环。总之,Foundry 就是数据中台,但又不止于数据中台;它是带“数据-决策-执行”闭环的企业级数据操作系统。
2)执行「对象构建(Build)」操作:在 Ontology Manager 中点击 Build按钮或者绑定的「源数据表」更新后,自动触发对象构建。总之,实际运作时,是在需要进行数据分析时通过映射关系直接读取「源数据表」的原始数据源,将数据映射到「属性表」中。
如上图所示,构建「属性表(Object Type Property Table)」时,从绑定的「源数据表」可全量或增量抽取数值:
全量重算Full Build:清空并重新生成属性表。
增量更新Incremental Build:仅处理新增 / 变更数据(需 Dataset 支持增量)。
03—【流程-数据模型】生成「本体模型」
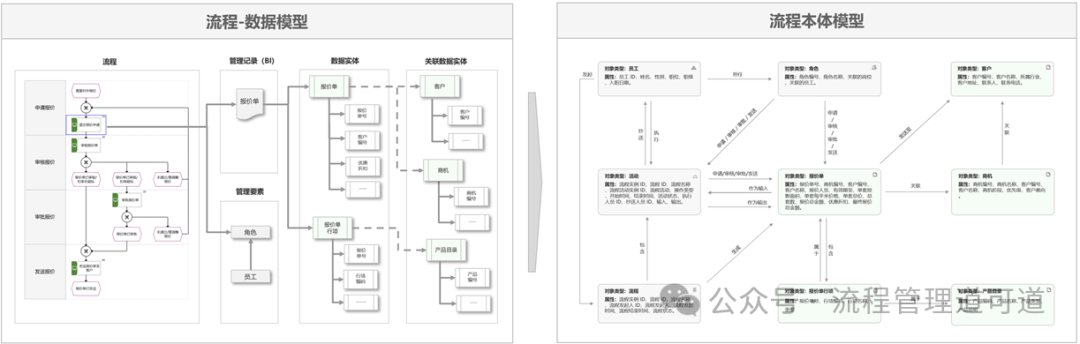
在 Palantir 的方法论中,「本体模型」及其与「源数据表」的映射关系都是由工程师团队直接在 Foudry平台上构建的。但是,EBPM 方法论认为 数据中台中的「本体模型」完全可以如上图所示,由业务架构建模平台中的【流程-数据模型】自动转换而来,即由业务模型驱动本体建模,在 “数据中台”上仅是完成映射工作。
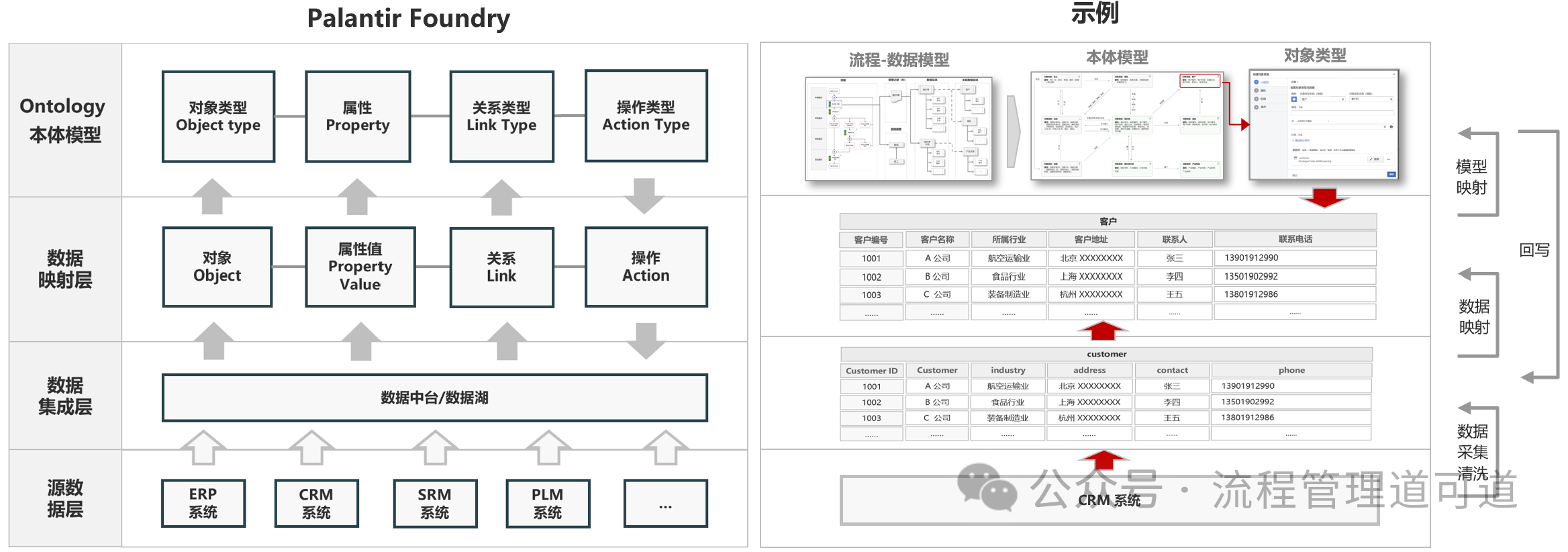
在上图右侧的示例中,将【流程-数据模型】加入了业务过程数字化的工程化落地过程。
04—“业务过程数字化”的关键成功因素
总结一下。EBPM 方法论认为,“业务过程数字化”就是要构建“模型+数据”的 “业务数字孪生体”,并基于此孪生体构建业务过程的PDCA 管理闭环。具体过程是:
基于企业架构原理和流程管理方法构建【流程-数据模型】。
将【流程-数据模型】直接推送给数据中台,并转换成「本体模型」。
在数据中台上完成「本体模型」与「源数据表」的映射。
在此基础上构建 “数据+模型” 驱动的监控、分析、决策、执行的功能。
以上就是“业务过程数字化”工程化落地的具体操作过程。这个过程的关键成功因素是以下三点。
1)要有“工具平台”。需要有类似 Palantir Foundry 这样的软件工具平台。EBPM 方法论认为,现有的 【BPA(业务流程建模工具平台)+数据中台】的组合,应可以提供足够的支撑。当然,如果要实现 AI 能力的融入,还要增加类似 Palantir AIP 这样的 AI 智能体构建和管理平台。
2)要能 “取到数”。「本体模型」要能与「源数据表」映射,一定要有「源数据表」,也就是一定要能 “取到数”。就以本系列文章提到的【销售报价流程】为例,「员工」、「活动」、「流程」、「角色」、「报价单」、「报价单行项」、「客户」、「商机」、「产品目录」这 9 个「对象类型」都要能提供相应的「源数据表」。
可能有人要问,只能取到部分「对象类型」的数怎么办?那就只能构建部分「对象类型」的数字孪生管理体系。如果「活动」、「流程」这两个与过程相关的对象不能 “取到数”,那就只能实现业务对象的数字化管理,不能实现业务过程的数字化管理。
3)要能“映射”,即“数据”能匹配上“模型”。这是现在广泛存在的问题,也是很多企业没有出现类似 Palantir这样数字化应用效果的根本原因。
以 “流程” 为例,很多企业在 BPA 流程建模平台、BPM 工作流平台、BPI 流程挖掘平台上分别构建了三套流程模型,且这三套模型往往互不一致。即便能够获取到数据,也面临着究竟向哪套模型进行数据映射的困境。
再如,部分企业在数据架构与业务架构中各定义了一套 “业务对象”,二者同样常常无法对齐。即便取到了数据,也同样面临向哪套模型进行数据映射的问题。
因此,构建一套统一的企业管理体系模型,并以这套统一模型作为唯一的数据映射基准,是业务过程数字化成败的关键。按照 Palantir 的设计逻辑,企业只应存在一个业务语义层,这就是其核心的「本体模型」。
从哲学层面来看,本体论(Ontology)的核心是研究存在的本质,探讨世界的基本实体、实体的分类与本质属性,以及实体间的根本关系。
在企业管理数字化转型中,我们将对企业运行本质的认知成果 —— 包括管理要素的构成、本质、分类及其相互关系 —— 显性化为一套「本体模型」,并将其确立为全企业唯一的权威语义基准,所有流程、数据与系统均需对齐该本体。
这也很可能是 Palantir 将这套核心模型命名为 “本体模型” 的深层原因。
总结一下,EBPM 方法论认为,所谓 “数智化管理”,就是基于企业架构(EA)的原理构建管理体系4A模型;再将模型中的【流程 - 数据模型】映射与转换为「业务本体模型」,并将执行系统中的业务实例数据动态映射至该本体模型之上,形成可观测、可推演的业务数字孪生体;最终基于该孪生体,实现数字化与智能化的 PDCA 管理闭环。
本公众号后续将继续与大家分享实践 “企业架构-【流程-数据模型】-「业务本体模型」-数字孪生体-数智化管理” 这一实践路径的案例和心得。
 原 文
原 文 
 评 论
评 论 