



1.预测的2个著名原理
第1个是近期预测的准确性高于远期的。大家可以想象一下天气预报,气象台预测明天的天气一般都是很准的,气温是几度,会不会下雨,准确率高得惊人。
第2个是汇总的预测比分离的预测更准确。这是什么意思呢?汇总和分离在供应链中的术语分别是Aggregate和Disaggregate,从单词的前缀上看得出它们是一对反义词。
比如说,某种特定颜色的体恤衫的需求就是分离预测,我们很难预测蓝色、黑色、黄色或是粉色衣服分别能卖出多少件,因为个体商品的需求波动性很大。
如果我们把这些体恤衫的需求汇总起来,在产品系列的层面上预测就会准很多。每种体恤衫的需求过高和过低的可能性是一样的,低估往往能平衡高估的数字,它们可以相互抵消。
这是一种非常奇妙的现象,它的原理是风险分担(Risk Pooling),意思是把个别的风险合并到同一个池子里,而池子里的总体风险往往小于流入池子的所有风险的平均值。
风险分担的效果依赖于大数定律,即随着参与风险分担的个体数量的增加,整体损失的波动性降低,从而使得每个人的风险降低。
根据预测的这2条原理,我们可以从时间远近和分离汇总这2个维度出发,把需求计划分为4个象限。
2.需求计划的4个象限
1)象限1:尽量避免
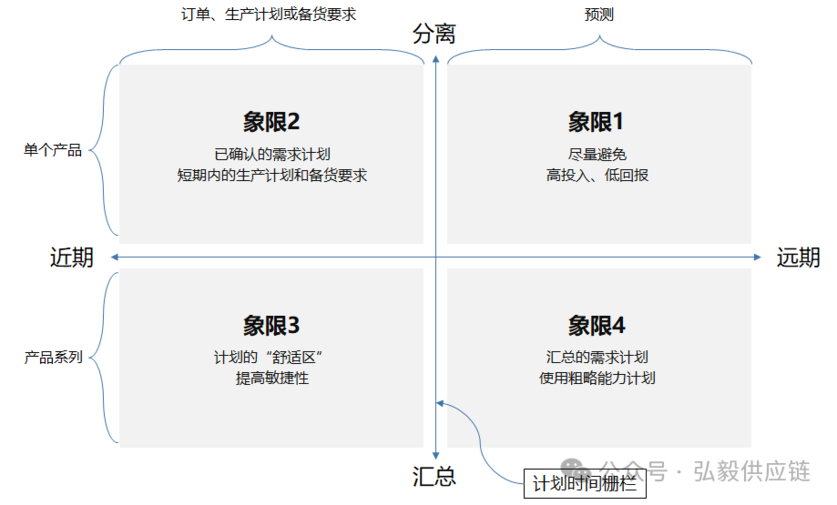
这个象限对预测工作是非常不利的。如果我们对单个产品做预测,颗粒度非常小,这意味着巨大的工作量。
此外,我们还要预测远期的情况,它会降低准确性。两个负面的因素叠加在一起,导致我们花费了大量的时间去预测,但是准确率很低,属于是“高投入,低回报”,所以要尽量避免这个象限。
2)象限2:已确认的计划
在讨论这个象限之前,请大家思考一下如何设立近期和远期的分界线?我们可以使用计划时间栅栏(Planning time fence)。
根据定义,在栅栏之内的需求已经被转化为了已确认的订单,客户已经把这些订单发布给了供应商,后者无需预测,只需要把这部分的信息整理汇总即可。
如果是做寄售库存模式,客户会提供一个短期内的生产计划和对供应商的备货要求,这些信息的作用等同于订单。
如果企业实施了ERP系统,每次运行物料需求计划以后,系统会立即发送相关的订单或备货计划给供应商,大幅提高了信息传输的速度。
客户企业需要确保时间栅栏之内的信息是真实可靠的,信息一旦发送给了供应商,后者就会执行这份计划,而客户也应该在约定的时间之内安排提货。
3)象限3:计划的“舒适区”
在这个象限里的需求计划是近期的,而且是汇总层面的,相对于另外3个象限来说,这里的计划是最容易做的。
有些人可能会说“如果把时间栅栏设置得足够长,需求计划就会更准,因为我们收到的都是客户已确认的订单。”事实真的是这样吗?
预测原理的第2条是远期预测的准确性低于近期的。随着时间的推移,如果出现了需求下降的情况,即便客户发布了已确认的订单,他们仍会提出计划推后(Reschedule out)的要求,即推迟提货的安排。
供应商做好的订单变成了某种意义上的“安全库存”,请注意这不是真的safety stock,只是客户暂时不想要,放置在供应商仓库里的存货,所有权也属于后者。这种做法是客户变相转移库存风险的一种手段。
如果理解了这点,我们就会知道订单的提前期并不是越长越好。只要产能充足,供应商可以向客户申请更短的交货时间。这样做有几点好处。
首先,从接单到出货的时间缩短了,这意味着供应商可以更早地开票给客户,加快资金回笼。其次,较短的提前期可以减少计划推后出现的次数,降低供应商持有库存的风险。
象限3看似是需求计划的舒适区,但我们依然要想尽办法缩短订单的提前期,提高计划的敏捷性。
值得注意的是,缩短提前期并不意味着削减需求计划的时间跨度,关于这个话题请看这篇文章《为什么需求计划的时间跨度要18个月?给你五点原因,两个解决方案》。
3)象限4:汇总的需求计划
通过前面3个象限的介绍,相信大家已经理解了需求计划的要点,在第4个象限里,最好的做法是仅做汇总层面的需求计划,即预测产品系列或是产品家族,这比预测单品的准确性要高许多。
我们可以使用粗略产能规划(Rough-Cut Capacity Planning,简称RCCP),它是一种长期的产能规划工具,用来验证主生产计划的可行性,确保企业拥有满足计划生产所需的必要劳动力和原材料。
比方说,工厂有5个产品系列,总共100个单品。如果要预测一年后的产能是否可以满足所有的需求,我们不需要去考虑所有的产品,只要在产品系列层面预测即可。
我们可以算出每款单品的产能,但是如何在混合生产的动态环境中清楚地计算出详细的数字?这是非常困难的事情,而且实际的需求与预测之间肯定会有偏差。
如果预测了每个单品的远期的需求,就会落入第一象限之中,而那里是我们要避免进入的区域。因此,我们仅在计划时间栅栏内才需要做详细的规划,在此之外仅需做汇总的需求计划。
 原 文
原 文 